インターネットで情報を探している際、多くのタブを同時に開いて作業をすることはありませんか。
例えば、あるトピックについて調査をしながら、別の画面でスケジュールを調整し、さらに別の画面で連絡事項の下書きを作成するといった状況です。
こうした複数の作業を並行して行う場合、画面やタブを切り替える動作が頻繁に発生します。この切り替え作業は、無意識のうちに作業効率を低下させ、それまで維持していた集中力を削いでしまう要因となります。
現在開いている画面から移動することなく、必要な情報の処理や関連する操作を完結させたい。
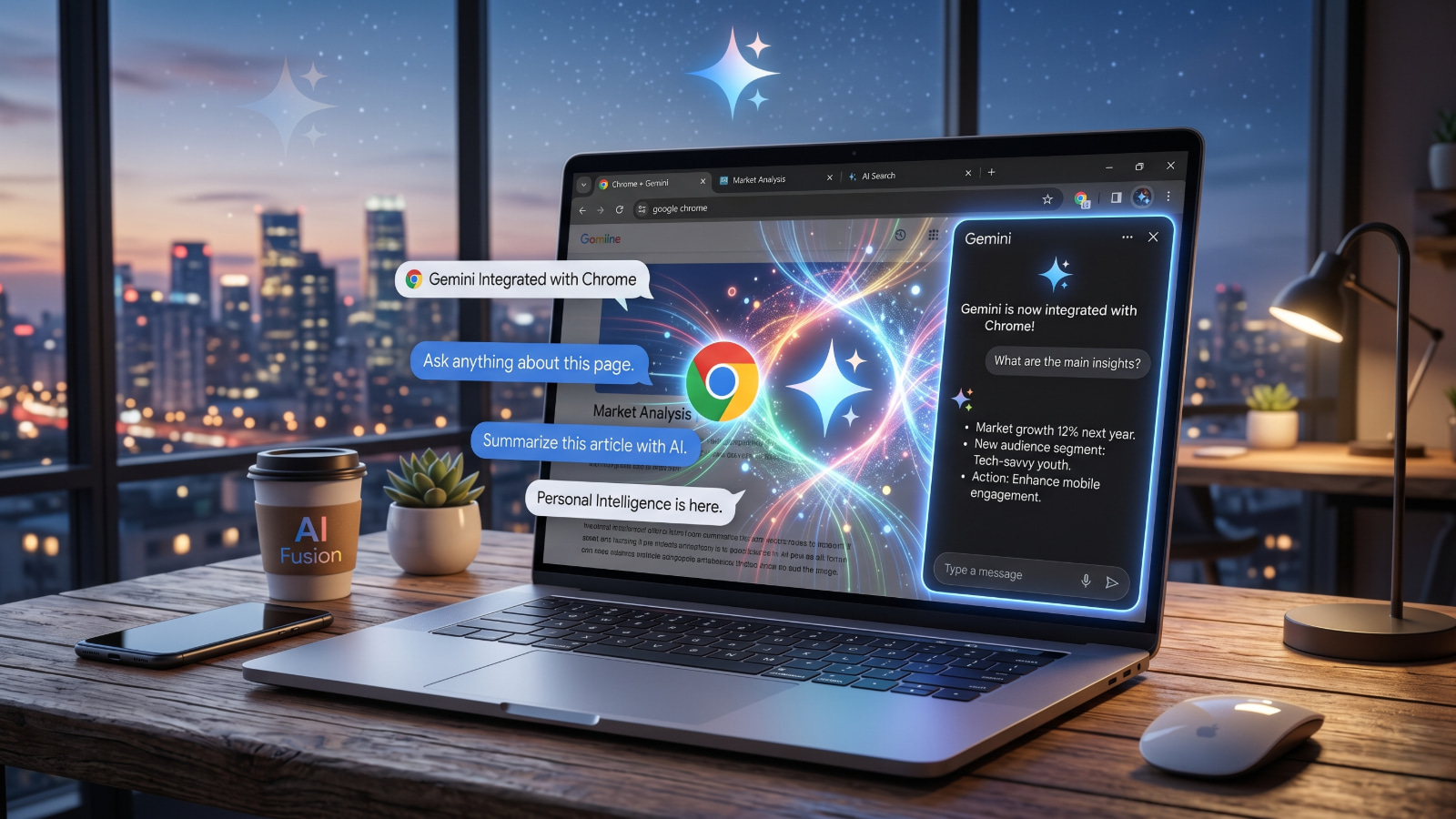
そうした要望に対応する新しい機能**「Gemini in Chrome」が、ついに日本を含むアジア太平洋地域でも順次展開されることが発表されました。**
今回は、ブラウザでの作業環境を向上させるこの機能について詳しく解説します。
サイドパネルで利用できるAI支援機能
Gemini in Chrome は、ブラウザのサイドパネルから直接AI(人工知能)を呼び出し、ユーザーの作業を多角的に支援する機能です。
特別なソフトウェアを個別に立ち上げる必要はなく、ブラウザのサイドパネルを有効にするだけで、現在閲覧しているウェブページの内容に基づいた高度な操作が行えます。
- **情報の整理と要約:**専門的で長い文章の内容を短くまとめ、重要なポイントを即座に抽出できます。また、複数のタブにまたがる情報をサイドパネル上で一括して比較検討することも可能です。
- **Googleサービスとの直接連携:**ページを離れることなく、Google カレンダーへの予定登録、Google マップでの場所確認、Gmailでの下書き作成が行えます。さらには、視聴中のYouTube動画の内容に対して具体的な質問を投げかけ、回答を得ることも可能です。
- **画像の変換・編集:**画像生成・編集モデル「Nano Banana 2」により、ウェブ上の画像をテキストでの指示に基づいて、その場で加工・編集できます。

mimihokuro
実はFirefoxのような他のブラウザではサイドパネルからAIを呼び出す機能があったのですが、Chromeは実装がされておらず、個人的にはまだかまだかと待ち焦がれていました。
作業効率を向上させる3つの主要な特徴
この新機能が日々のPC作業において、具体的にどのような利便性をもたらすのか、その詳細を3つの項目に整理しました。
1. 作業の継続性を高める操作体系
これまでは「調べる」「記録する」「送信する」といった工程ごとに、異なるアプリケーションやタブへ切り替える必要がありました。
Gemini in Chromeは、これらをサイドパネル内で一括して処理できるように設計されています。
例えば、解説動画を視聴しながら不明な点をサイドパネルで確認し、得られた回答をそのまま同じ画面上で資料に反映させるといった、一連の動作が途切れることなく実行可能です。
2. 文脈に応じた情報提供(Personal Intelligence)
本機能は、単一の質問に対する定型的な回答を返すだけではありません。「Personal Intelligence」により、過去のやり取りの経緯や、現在どのページを見ているかといった「文脈(コンテキスト)」をふまえた情報を提供してくれます。
これにより、ユーザーが状況を一から説明し直す手間を省き、より適切かつ精度の高い回答を得やすくなります。使えば使うほど、ユーザーの意図を汲み取った支援が可能になる点が大きな特徴です。
3. 画像の生成・加工プロセスの簡略化
最新の画像モデル「Nano Banana 2」が、ブラウザ上での画像処理を直接サポートしてくれるようになります。
例えば、ウェブサイト上の素材の色調を変更したり、特定の要素を追加したりといった作業が、専用の画像編集ソフトウェアを起動することなく、指示文の入力のみで完結します。
ブラウザ内ですべての処理が完結するため、ファイルの保存や再アップロードといった付随的な手間が大幅に削減されます。
情報の閲覧から活用へ
今回のアップデートは、ブラウザの役割を「情報を閲覧するツール」から「情報を処理し、具体的に活用するための環境」へと広げるものです。
頻繁な画面切り替えによる視覚的・心理的な負担を軽減し、ユーザーが本来時間をかけるべき思考や実務作業に専念できる環境が整いました。
今回の発表はGoogle愛用者(特にGemini派)にはとんでもなく嬉しい発表でしたが、「順次」ということで、執筆時点(2026年4月21日)ではまだ日本では使えませんでした。
とはいえ、いよいよChrome上でGeminiが使えるということで、ブラウジングがますます便利になることは間違いありません。
Chromeアップデートが走りましたら、また追記していきたいと思います。
4月27日時点で私の環境で実装が確認できました!まだ確認できていない場合はChromeのアップデートを確認してみてください。それでも表示されない場合はまだ展開待ちの状況なので今しばらくの辛抱です。
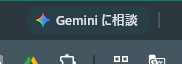
適用されるとChromeの右上にボタンが表示されます